Zwischenbericht der FDM-Landschaftsvermessung des Zentralprojekts
von Patrick Helling
Eine Kernaufgabe des Zentralprojekts im DFG Schwerpunktprogramm „Computational Literary Studies“ (SPP CLS) ist die Entwicklung von passgenauen Lösungsstrategien für das Management digitaler Forschungsdaten sowie allen weiteren Ergebnissen aus Forschungsprozessen für die im SPP CLS angesiedelten Projekte. Dies umfasst alle Aspekte rund um den Forschungsdatenlebenszyklus von der Analyse, effektiven Verwaltung und Sicherung digitaler Daten während der Projektlaufzeit über das kollaborative Arbeiten an Forschungsdaten bis hin zur Definition von Beschreibungsstandards, der Entwicklung von Best Practices für den Fachbereich sowie die strukturierte Archivierung, Publikation und nachhaltige Verfügbarmachung von Forschungsdaten und Ergebnissen von Forschungsprozessen.
Um konkrete Bedarfe und Bedingungen in Bezug auf das Management von Forschungsdaten innerhalb des SPP zu identifizieren sowie zur Erfassung von für das Forschungsdatenmanagement (FDM) relevanten Informationen aus den einzelnen Projekten, führt das Zentralprojekt leitfadengestützte, virtuelle Interviews mit Vertreter*innen aller Projekte des Schwerpunktprogramms durch.
Ziel ist dabei (1) eine umfassende Landschaftsvermessung in Bezug auf die jeweiligen Strukturen, Methoden, Vorgehensweisen und FDM-Bedarfe der einzelnen Projekte zur Konsolidierung des Forschungsdatenmanagements im SPP CLS, (2) die bedarfsorientierte Entwicklung von Best Practices/Empfehlungen und konkreter FDM-Lösungsstrategien sowie (3) die Beförderung von Synergien und eines kontinuierlichen Kompetenzaustausches zwischen den einzelnen Projekten.
Struktur des Leitfadens
Der Leitfaden für die Interviews umfasst zwei Fragenkomplexe, einerseits zu FDM-relevanten Aspekten (A) im laufenden Projekt, andererseits zu FDM-relevanten Aspekten (B) am Ende des Projekts. I.d.R. handelt es sich bei den Fragen um offene Fragen. Konkret gliedert sich der Leitfaden in folgende Grundstruktur auf:
A – im laufenden Projekt
- A.1 Arbeit mit Daten
- Sektion 1: tägliche Arbeit mit Daten
- Sektion 2: Status im Projekt
- A.2 Datenmanagement im Projekt
- Sektion 1: Zusammenarbeit im Projekt
- Sektion 2: Datensicherung während des Projekts
- A.3 Entwicklung lebender Systeme
- Sektion 1: Status lebender Systeme
B – am Ende des Projekts
- B.1 Umgang mit Daten am Ende des Projekts
- Sektion 1: Archivierung
- Sektion 2: Publikation
- B.2 Umgang mit lebenden Systemen am Ende des Projekts
- Sektion 1: Betrieb von lebenden Systemen
In den beiden zentralen Fragenkomplexen (A und B) werden unter anderem die Nutzung von Programmen und Tools, Programmier- und Skriptsprachen, Datenformaten und Standards, aber auch angewendete wissenschaftliche Methoden und regelmäßige, datenbezogene Arbeiten abgefragt. Zusätzlich spielen insbesondere Aspekte des kollaborativen Arbeitens, Backup-Strategien, Archivierungs- und Publikationsmodelle eine zentrale Rolle.
In zwei kleineren Abschnitten zu lebenden Systemen werden gleichzeitig Informationen über genutzte Technologie-Stacks, Funktionsumfang, Sicherung und Verfügbarkeit von selbst entwickelten, dynamischen Anwendungen, Präsentationsformen, interaktiven Visualisierungen, Tools, Datenbanken, Websites u. Ä., die in gleichem Maße Ergebnisse von Forschungsprozessen sowie zentrale Zugangsschicht zu Forschungsdaten darstellen können, abgefragt.
Darüber hinaus werden in einem dritten Fragenkomplex insbesondere (C) Erwartungen an das zentrale Forschungsdatenmanagement und somit an das Zentralprojekt selbst abgefragt, die im Kontext dieser Auswertung allerdings keine Rolle spielen.
Der gesamte Leitfaden ist unter einer CreativeCommons-Lizenz hier zur Nachnutzung zugänglich.
Durchführung der Interviews und erste Verarbeitung der erhobenen Daten
Die Interviews mit Vertreter*innen der einzelnen Projekte werden seit Mai 2020 über das Videokommunikations-Tool Zoom virtuell durchgeführt. Die Teilnehmenden erhalten den Leitfaden vor dem Gespräch zur Einsicht und werden gebeten eine Datenschutzvereinbarung zur Erhebung, Verarbeitung und Speicherung der Daten zu unterzeichnen. I.d.R. führen zwei Mitarbeiter*innen des Zentralprojekts an Hand des Leitfadens durch die Gespräche. Die Audiospur der Interviews werden aufgezeichnet.
Die dabei entstehenden Audiodaten werden im Anschluss an die Interviews ausgewertet, die gegebenen Antworten werden nach einem eigenen Kategoriensystem strukturiert und in eine Excel-Tabelle geordnet übertragen. Die Audiodaten werden bis zum Ende des Zentralprojekts auf einem institutionellen Speicher der Universität Würzburg gesichert und im Anschluss gelöscht.
Erste Ergebnisse der Datenerfassung
Die im Folgenden dargestellten Ergebnisse stellen lediglich einen aktuellen Zwischenstand (Februar 2021) dar.
Alle Projekte befanden sich zum Zeitpunkt der Gespräche in unterschiedlichen Stadien des Projektbeginns. Im Rahmen der Gespräche wurden i.d.R. offene Fragen gestellt, wodurch im Laufe der Interviews viele weitere Antwortkategorien identifiziert werden konnten. Im Anschluss an die Gespräche hat daher ein inhaltliches Review der individuellen Ergebnisse durch die einzelnen Projekte stattgefunden. Durch die Abbildung der vielen im Prozess entstandenen, individuellen Antwortkategorien war es entsprechend möglich nachträgliche Ergänzungen in Bezug auf die ursprünglich gegebenen Antworten von nahezu allen Projekten zu erhalten und somit auch eine weitere Ausdifferenzierung der Ergebnisse zu erreichen.
Der Review-Prozess wurde im Januar 2021 abgeschlossen. Aufgrund dessen, dass sich die Projekte zu diesem Zeitpunkt noch in der ersten Hälfte des Forschungsdatenlebenszyklus befanden, wurden im Review-Prozess die Themenkomplexe Archivierungs- und Publikationsstrategien sowie Fragen zu lebenden Systemen noch nicht mit abgedeckt. Für diese Abschnitte des Leitfadens ist eine weitere Review-Phase für Ende 2021 geplant.
Tägliches Arbeiten mit Daten
Bei der täglichen, datenbezogenen Arbeit lässt sich eine große Bandbreite innerhalb des SPP erkennen (siehe Diagramm 1). Insbesondere Annotationen spielen im Rahmen der einzelnen Projekte eine zentrale Rolle. Die Erstellung (8) bzw. die automatische Generierung von Annotationen (7) wurden entsprechend häufig als datenbezogene Arbeiten genannt. Da die Mehrheit der Projekte zum Zeitpunkt der Befragung noch weitestgehend am Anfang ihrer Laufzeit stand, spielen entsprechend Tätigkeiten wie die Datenbereinigung (8), der Aufbau von Korpora (7) und die Datenkonvertierung (5) bei vielen Projekten noch eine zentrale Rolle.
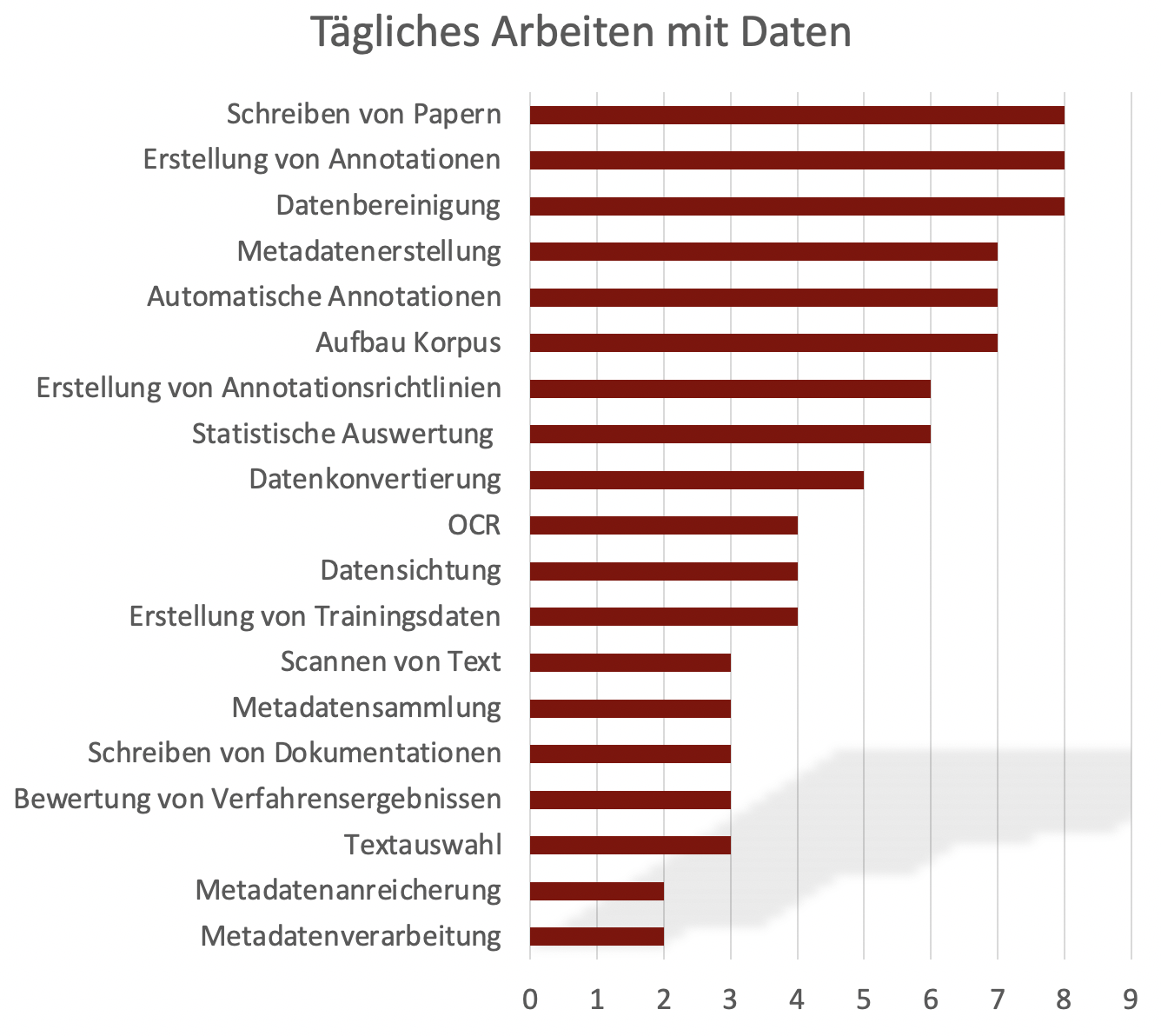 Diagramm 1: Tägliche, oder zumindest regelmäßige, datenbezogene Arbeiten innerhalb der einzelnen Projekte.
Diagramm 1: Tägliche, oder zumindest regelmäßige, datenbezogene Arbeiten innerhalb der einzelnen Projekte.
Nutzung von Tools und Programmier-/Skriptsprachen
Zur Durchführung dieser datenbezogenen Arbeiten nutzen die einzelnen Projekte unterschiedliche Tools und Systeme. Für die Verwaltung der jeweiligen Projekte wurden Github und Gitlab (11) am Häufigsten genannt (siehe Diagramm 2). Mit den beiden Git-Systemen verwenden die meisten SPP-Projekte ein Tool, das sowohl das kollaborative Arbeiten als auch die Versionierung von Arbeit in den Vordergrund stellt.
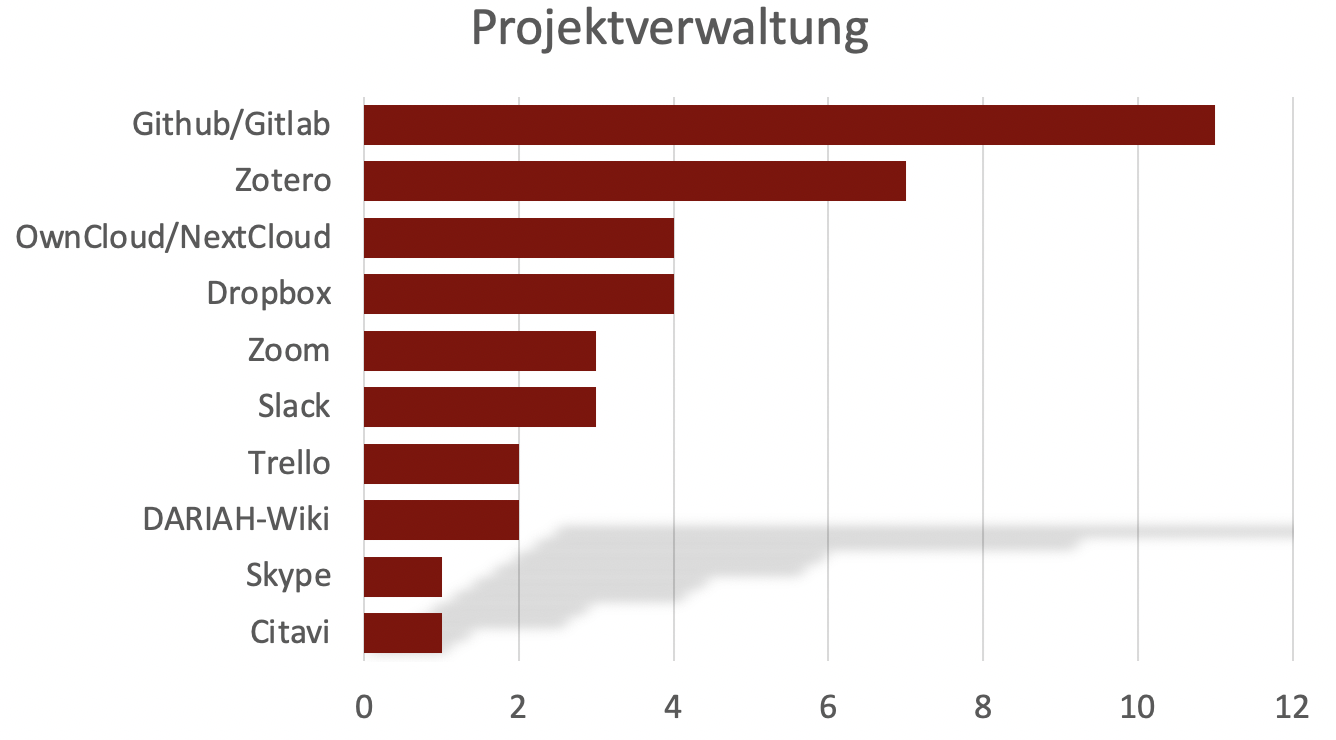 Diagramm 2: Nutzung von Tools und Systemen zur Projektverwaltung.
Diagramm 2: Nutzung von Tools und Systemen zur Projektverwaltung.
Bei der Nutzung von Anwendungen zur Textproduktion werden innerhalb des SPP einige unterschiedliche, sowohl proprietäre als auch freie Tools und Systeme verwendet (siehe Tabelle 1). Obwohl Annotationen eine zentrale Rolle in nahezu aller Projekte darstellen, haben mit Catma (5), TreeTagger (1), CorefAnnotator (1) und Sentiment Analyzer (1) lediglich acht Projekte die Verwendung eines entsprechenden Tools angegeben.
- Office: 7 Projekte
- Google Docs/Sheets: 6 Projekte
- LaTeX: 3 Projekte
- Sublime Text: 3 Projekt
- ShareLaTeX: 1 Projekt
- FidusWriter: 1 Projekt
Im Bereich der Programmier- und Scriptsprachen lässt sich eine eindeutige Verteilung im SPP erkennen: Insgesamt neun Projekte gaben an, dass sie bei ihrer Arbeit Python verwenden und immerhin vier Projekte nannten R (siehe Diagramm 3).
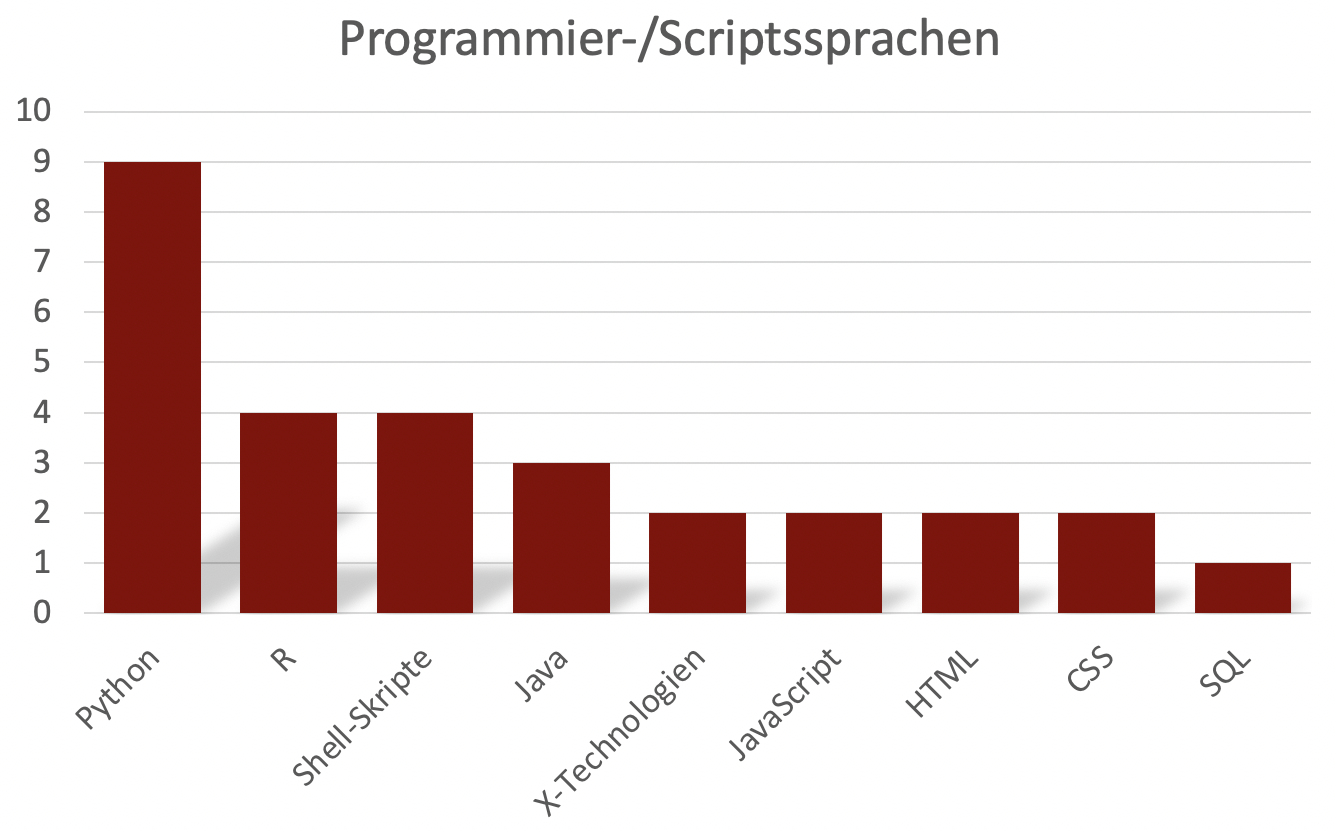 Diagramm 3: Genutzte Programmier- und Skriptsprachen im SPP CLS.
Diagramm 3: Genutzte Programmier- und Skriptsprachen im SPP CLS.
Wenngleich bei den genutzten Programmierumgebungen und Bibliotheken im Einzelnen eine große Heterogenität festzustellen ist, ist auch hier die flächendeckende Nutzung von Python, mindestens bei den Bibliotheken, erkennbar:
Bibliotheken:
- scikit learn (Python): 7 Projekte
- spacy (Python): 6 Projekte
- pandas (Python): 6 Projekte
- numpy (Python): 6 Projekt
- NLTK (Python): 5 Projekte
- Matplotlib (Python): 4 Projekte
- keras (Python): 3 Projekte
- Gorbid (Python): 1 Projekt
- NLP (R): 1 Projekt
- Drama Analysis (R): 1 Projekt
- CoNLL-U: 1 Projekt
Programmierumgebungen:
- Jupyter Notebooks: 5 Projekte
- div. Editoren: 5 Projekte
- oXygen: 2 Projekte
- RStudio: 2 Projekte
- Spyder IDE: 1 Projekt
- Google Colab: 1 Projekt
- Kaggle: 1 Projekt
- Eclipse: 1 Projekt
Datentypen und -formate
Text (10) und Softwarecode (9) wurden bei der Frage nach verwendeten Datentypen, entsprechend des gemeinsamen Fachbereichs, von allen Projekten angegeben (siehe Diagramm 4). Allerdings spielen auch numerische Daten (6) oder Bilddaten (5), bspw. in Form von Scans, eine wichtige Rolle, genauso wie bibliographische Daten (4).
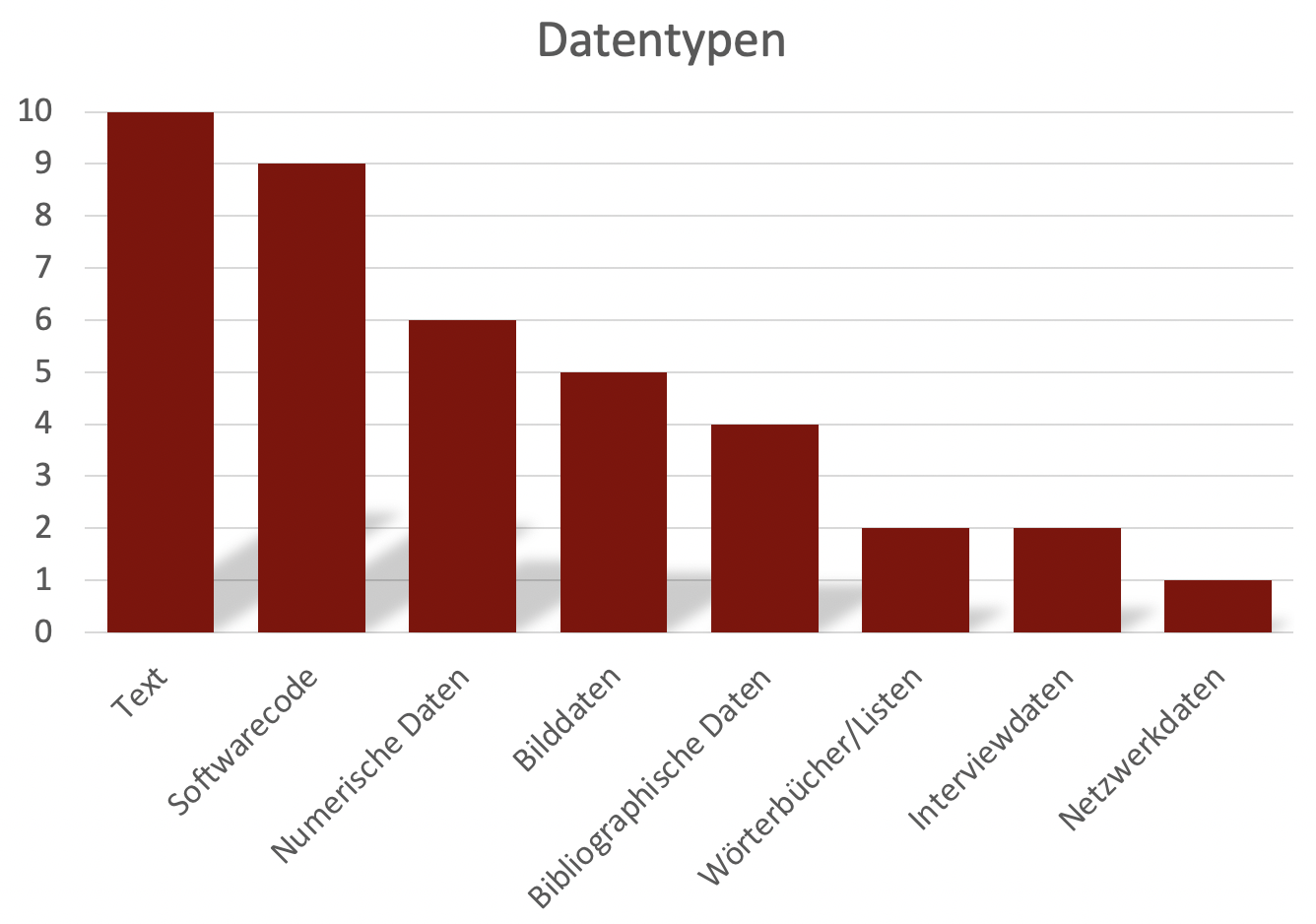 Diagramm 4: Genutzte Datentypen innerhalb des SPP CLS.
Diagramm 4: Genutzte Datentypen innerhalb des SPP CLS.
Den etablierten Standards und der Tradition der Fachrichtung folgend nutzen alle Projekte XML (10) als ein zentrales Datenformat (siehe Diagramm 5). Darüber hinaus wurden aber auch viele weitere Formate genannt, unter anderem CSV (8), Plain Text Formate (8), PDF (5) und allgemeine Wordformate (4).
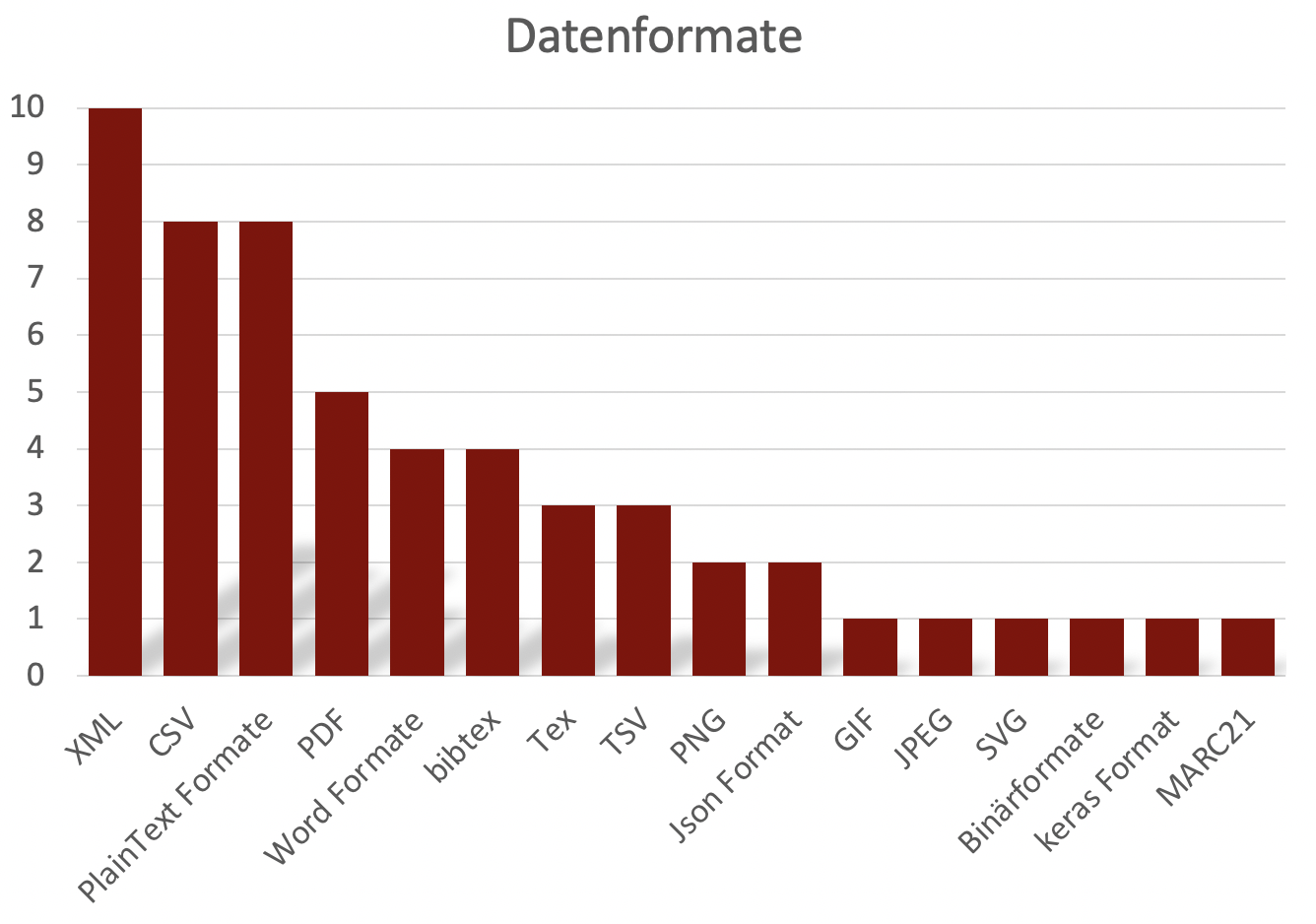 Diagramm 5: Genutzte Datenformate innerhalb des SPP CLS.
Diagramm 5: Genutzte Datenformate innerhalb des SPP CLS.
Angewendete, wissenschaftliche Methoden
Bei der Verarbeitung der unterschiedlichen Datentypen und -formate stellen, insbesondere aus fachlicher Perspektive, die angewendeten wissenschaftlichen Methoden innerhalb der einzelnen Projekte einen zentralen Aspekt dar. Wenngleich diese stark von der individuellen Forschungsfrage abhängen, lassen sich dennoch einige Methoden, wie bspw. die Word Embedding (7), Sentiment Analysen (6) und das Topic Modelling (5) identifizieren, die von mehreren Projekten angewendet werden (siehe Tabelle 3).
- Word Embeddings: 7 Projekte
- ML/Classifierentwicklung: 7 Projekte
- Sentimentanalyse: 6 Projekte
- Qualitative Inhaltsanalyse: 6 Projekte
- Analyse von annotierten Daten: 6 Projekte
- Part-of-Speech-Tagging: 6 Projekte
- Topic Modeling: 5 Projekte
- Stilometrie: 5 Projekte
- Netzwerkanalyse: 3 Projekte
- Named Entity Recognition: 3 Projekte
- Emotions Analyse: 3 Projekte
- Koreferenzerkennung: 3 Projekte
- Empirische Leserstudien: 2 Projekte
- Extraktion von Netzwerkinformationen: 2 Projekte
- Evaluation von Distinktivitätsmaßen: 2 Projeke
- Metadatenanalyse: 2 Projekte
- Erzähltextanalse/Textinterpretation: 2 Projekte
- Verfahren der Charakterbeschreibung: 2 Projekte
- Zeitformerkennung: 1 Projekt
- Anomaliedetektion: 1 Projekt
- Text Reuse Detection: 1 Projekt
- Citation Identification and Linking: 1 Projekt
- Hermeneutische Verfahren: 1 Projekt
- Erstellung kleinerer Bibliographien: 1 Projekt
- Entwicklung distributiver Semantik: 1 Projekt
Status und Perspektive lebender Systeme
Ein wichtiger Output von wissenschaftlichen Projekten können, neben Publikationen und Forschungsdaten, auch sogenannte lebende Systeme darstellen. Dies sind bspw. dynamische Anwendungen, Präsentationsformen und interaktive Visualisierungen, digitale Tools, Recherche-Datenbanken, Websites u. Ä., die auch zentrale Zugangsschichten zu weiteren Forschungsergebnissen darstellen können.
Sieben Projekte des SPP CLS planen mindestens eine Website zu erstellen. Darüber hinaus wurden unter anderem Tools/Anwendungen (3) und ein Dashboard als geplanter Output von Forschungsprozessen genannt:
- Website: 7 Projekte
- Tools/Anwendungen: 3 Projekte
- Bibliothek: 1 Projekt
- Dashboard: 1 Projekt
Neben der bereits genannten Funktionalität als Zugangsschicht zu Forschungsdaten 8) sollen die lebenden Systeme in vier Fällen explizit die Nachnutzung von Forschungsergebnissen (5) ermöglichen und auch ihre Visualisierung (3) spielt bei einigen SPP-Projekten in diesem Rahmen eine wichtige Rolle (siehe Diagramm 6).
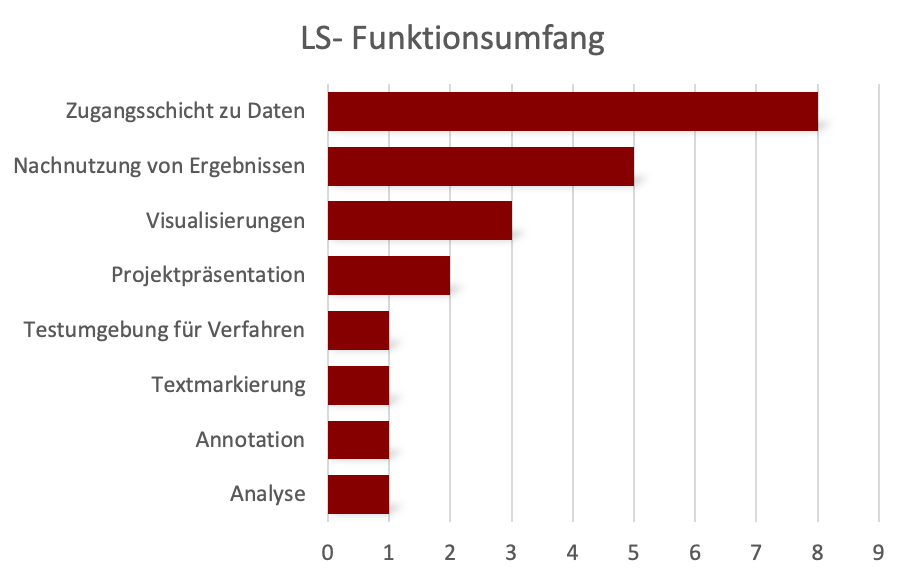 Diagramm 6: Funktionsumfang von lebenden Systemen, die im Rahmen des SPP CLS entwickelt werden sollen.
Diagramm 6: Funktionsumfang von lebenden Systemen, die im Rahmen des SPP CLS entwickelt werden sollen.
Datensicherung und Backup
Neben den bereits dargestellten Themenkomplexen, die inhaltlich und strukturell einen entscheidenden Einfluss auf das Forschungsdatenmanagement im Rahmen des SPP CLS haben werden, sind natürlich auch Aspekte wie Datensicherungs- und Backupstrategien während der Projektlaufzeit für das allgemeine Forschungsdatenmanagement von großer Bedeutung.
In diesem Zusammenhang hat jedes Projekt bei den Gesprächen angegeben entweder über eine zentrale und/oder eine (zusätzliche) individuelle Backup-Strategie zu verfügen. Dabei greifen sie auf unterschiedliche institutionelle lokale/übergreifende oder proprietäre Infrastrukturen zurück (siehe Diagramm 7).
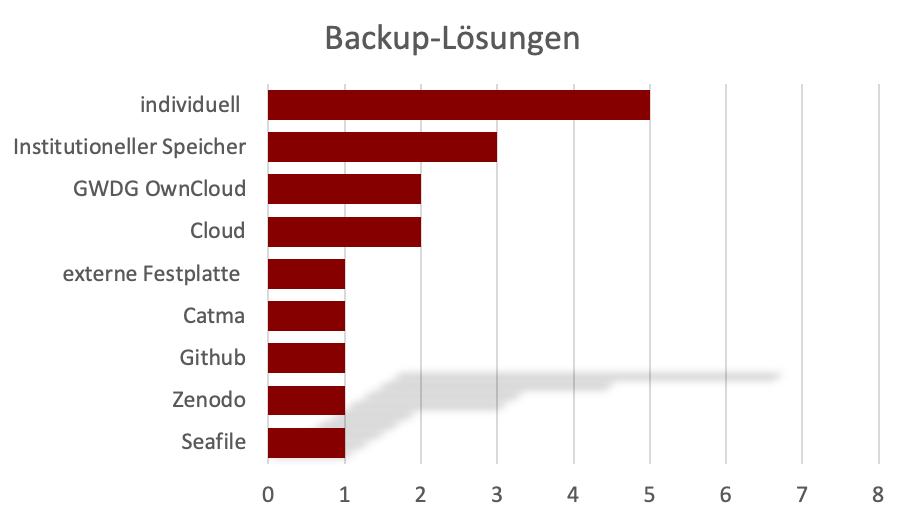 Diagramm 7: Unterschiedliche Backup-Lösungen innerhalb des SPP CLS.
Diagramm 7: Unterschiedliche Backup-Lösungen innerhalb des SPP CLS.
Archivierungs- und Publikationsstrategien
Schlussendlich stellt im Rahmen der Entwicklung einer gemeinsamen Forschungsdatenmanagement-Strategie für das gesamte SPP CLS insbesondere die Konsolidierung von Archivierungs- und Publikationslösungen einen zentralen Aspekt dar.
Sowohl für die Archivierung als auch die Publikation von Forschungsergebnissen spielen innerhalb der einzelnen SPP-Projekte Github/Gitlab (6 bzw. 5) und Zenodo (4 bzw. 6) eine wichtige Rolle. Beim Thema Publikation wurden, bspw. mit TextGrid (2), GerDraCor (1) oder dem Deutschen Textarchiv DTA (1), zusätzlich auch unterschiedliche fachspezifische Lösungen genannt (siehe Diagramm 8 und 9).
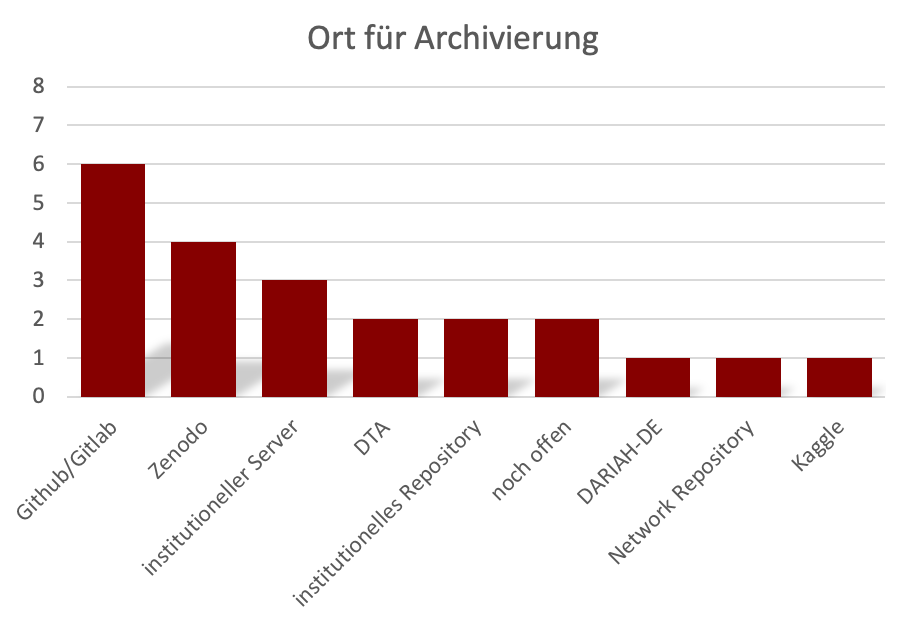 Diagramm 8: Orte, die für die Archivierung von Forschungsergebnissen für die Projekte des SPP CLS in Frage kommen.
Diagramm 8: Orte, die für die Archivierung von Forschungsergebnissen für die Projekte des SPP CLS in Frage kommen.
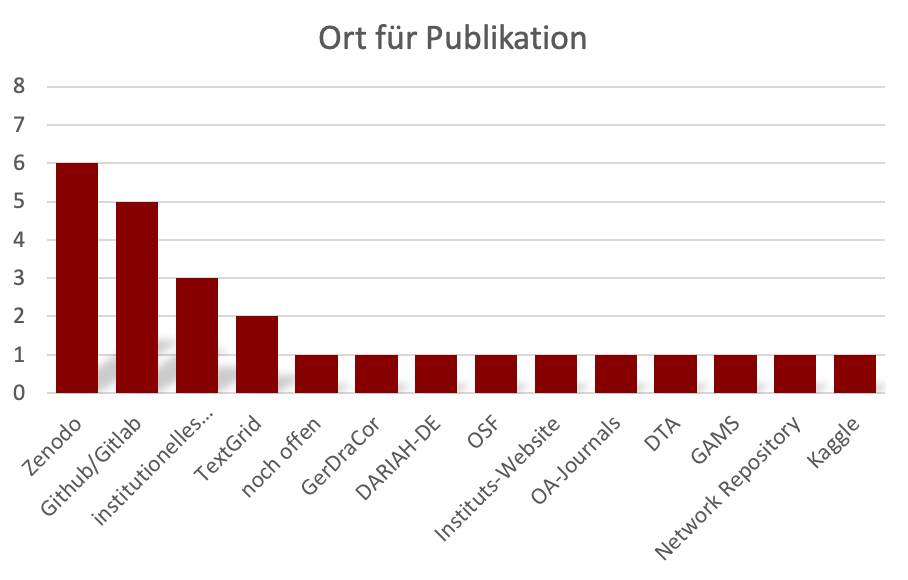 Diagramm 9: Orte, die für die Publikation von Forschungsergebnissen für die Projekte im SPP CLS in Frage kommen.
Diagramm 9: Orte, die für die Publikation von Forschungsergebnissen für die Projekte im SPP CLS in Frage kommen.
Zusammenfassung und nächste Schritte
Obwohl das Schwerpunktprogramm „Computational Literary Studies“ Projekte aus einem gemeinsamen Fachbereich vereint, stellt sich die Forschungsdatenlandschaft des SPP als äußerst komplex dar. Die unterschiedlichen Projekte verfügen über individuelle infrastrukturelle Ausstattungen, setzen verschiedene datenbezogenen Arbeiten um und generieren heterogene Ergebnisse aus ihren jeweiligen Forschungsprozessen, nicht nur i.S.v. Forschungsdaten, sondern insbesondere auch im Bereich lebender Systeme. Darüber hinaus sind alle Projekte interdisziplinär ausgerichtete, wissenschaftliche Vorhaben innerhalb der Digital Humanities, bei denen unterschiedliche Fachtraditionen mit jeweils eigenen Standards und Best Practices zusammenkommen.
im Rahmen der Landschaftsvermessung konnten bereits individuelle FDM-Kompetenzen bei einzelnen Projekten identifiziert werden, bspw. in den Bereichen verschiedener Datentypen oder angewandter Forschungsmethoden, bei der Nutzung und auch Entwicklung von Software und Tools sowie der Verwendung bestimmter Technologie-Stacks. In der Breite lassen sich hingegen dennoch einige verbreitete Standards und Best Practices erkennen, wie bspw. bei der Verwendung von Datenformaten, Programmier- und Skriptsprachen sowie der Akzeptanz bei der Nutzung bestimmter Tools und Systeme.
Die gewonnenen Ergebnisse ermöglichen es nun einerseits individuelle FDM-Kompetenzen aus den einzelnen Projekten in das gesamte SPP CLS zu tragen, andererseits dienen bereits bestehende Standards und Best Practices als Basis zur Entwicklung einer fachspezifischen FDM-Gesamtstrategie für das SPP CLS.
Folglich werden die Ergebnisse im nächsten Schritt weiterführend ausgewertet, um
- das Datenmanagement während der Projektlaufzeit zu konsolidieren und ggf. infrastrukturelle Lösungen zu entwickeln/bereitzustellen
- den Kompetenzaustausch und die Nutzung von Synergien innerhalb des SPP CLS in Bezug auf das Management von Forschungsdaten zu befördern und
- entsprechende Best Practices und Empfehlungen für das gesamte SPP CLS zu entwickeln.
Letzteres umfasst dabei, orientiert an der Summe aller Bedarfe, Strukturen und Standards innerhalb des SPP, sowohl die Evaluation bestehender FDM-Workflows und -Strategien der einzelnen Projekte als auch die Formulierung einer SPP-Gesamtstrategie für die Archivierung, Publikation und langfristige Replizierbarkeit und Nachnutzbarkeit von Forschungsdaten und lebenden Systemen.
Diese FDM-Gesamtstrategie des SPP CLS könnte somit schlussendlich auch eine Art Blaupause für den gesamten Fachbereich der Computational Literary Studies fungieren und die Basis für weitere Entwicklungen innerhalb eines fachspezifischen Forschungsdatenmanagements darstellen.